[Database] Connection Pool
커넥션 풀을 알아보기 전에 먼저 데이터베이스(DB) 커넥션과 JDBC를 알아보자.
🕍 DB Connection란?
DB와 애플리케이션 간 통신을 할 수 있는 수단이다.
DB Connection은 Database Driver와 DB 연결 정보를 담은 URL이 필요하다. Java의 DB Connection은 주로 JDBC를 이용한다.
DB Connection 구조
- 2-Tier: 클라이언트로서의 자바 프로그램(ex: JSP)이 직접 DB 서버에 접근하여 데이터를 엑세스하는 구조
- 3-Tier: 자바 프로그램과 DB 서버 사이에 미들웨어 계층이 존재하는 구조
- 미들웨어 계층은 비즈니스 로직 구현, 트랜잭션 처리, 리소스 관리 등을 담당
🌁 JDBC란?
JDBC(Java Database Connectivity)는 자바를 이용해 다양한 종류의 RDBMS와 접속하고 SQL문을 수행하여 처리하고자 할 때 사용되는 표준 SQL 인터페이스 API다.
원래라면 프로그램을 DB와 연결할 때 DB마다 연결 방식과 통신 규격이 따로 있기 때문에 해당 DB와 관련된 기술적 내용을 알아야 한다. 또한 DB가 변경될 시 많은 변경사항이 존재한다.
하지만 각 DBMS에 맞는 JDBC를 받아주게 되면 쉽게 DBMS를 변경할 수 있다.
JDBC API를 사용하는 애플케이션의 구조는 자바 애플리케이션 → JDBC API → JDBC Driver → DB 로 구성된다.
JDBC Driver
자바 프로그램의 요청을 DBMS가 이해할 수 있는 프로토콜로 변화해주는 클라이언트측 어댑터이다. 각 DBMS 제공자는 자신에게 알맞는 JDBC Driver를 제공한다.
🍑 Connection Pool
🐤 사용하는 이유
자바에서 DB에 직접 연결해서 처리하는 경우 JDBC Driver를 로드하고 커넥션 객체를 받아와야한다. 매번 사용자가 요청을 할때마다 드라이버를 로드하고 커넥션 객체를 생성해 연결하고 종료하기 때문에 비효율적이다. 이를 해결하기 위해 커넥션 풀을 사용한다.
🏮 개념
웹 컨테이너가 실행되면서 일정량의 Connection 객체를 미리 만들어서 Pool에 저장했다가,
클라이언트 요청이 오면 Connection 객체를 빌려주고
해당 객체 임무가 완료되면 다시 Connection 객체를 반납해 Pool에 저장한다.
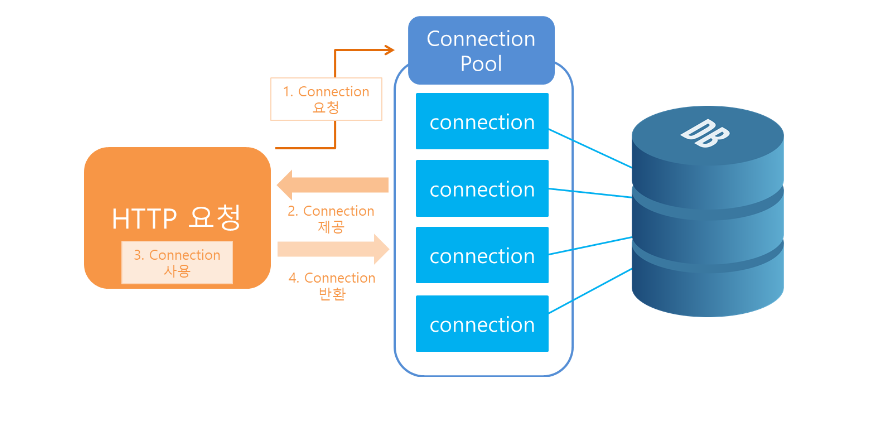
Connection Pool의 종류로는 “common-dbcp2”, “tomcat-jdbc Pool”, “DrvierManager DataSource”, “HikariCP” 등이 있다.
스프링 부트 2.0 이후부터는 커넥션 풀을 관리하기 위해 HikariCP를 채택하여 사용하고 있다.
🌈 장점
- DB 접속 설정 객체를 미리 만들어 연결하여 메모리 상에 등록해 놓기 때문에 불필요한 작업(connection 생성, 삭제)이 사라지므로 클라이언트가 빠르게 DB에 접속이 가능하다.
- DB Connection 수를 제한할 수 있어서 과도한 접속으로 인한 서버 자원 고갈 방지가 가능하다.
- DB 접속 모듈을 공통화하여 DB 서버의 환경이 바뀔 경우 쉬운 유지 보수가 가능하다.
- 연결이 끝난 Connection을 재사용함으로써 새로 객체를 만드는 비용을 줄일 수 있다.
🌵 주의사항
Connection의 주체는 Thread이기 때문에 Thread와 함께 고려해야 한다.
- Connection Pool을 너무 작게 설정하면 그만큼 대기시간이 늘어난다.
- Connection Pool을 너무 크게 설정하면 메모리 소모가 크다.
- Thread Pool 크기 < Connection Pool 크기
- Thread Pool에서 트랜잭션을 처리하는 Thread가 사용하는 Connection 외에 남는 Connection은 실질적으로 메모리 공간만 차지한다.
- Thread Pool 크기와 Connection Pool 크기 모두 증가
- Thread 증가로 인해 더 많은 Context Switching이 발생해 부정적인 영향을 미칠 수 있다.
🌺 적절한 Connection Pool 크기 설정
HikariCP 공식 문서에서는 아래와 같이 커넥션 풀 사이즈를 제안한다.
$connection = ((core_count) * 2) + effective_spindle_count$
core_count: 현재 사용하는 서버 환경에서의 CPU 개수
effective_spindle_count: DB서버가 동시 관리할 수 있는 I/O 요청 수
Dead lock -> 스레드 개념 이해하게되면 다시 정리하기 https://hudi.blog/dbcp-and-hikaricp/
참고
Leave a comment