[Redis] Redis 사용법 익히기
🍅 Redis 설치
이곳으로 이동해 설치 프로그램을 다운하고 설치를 진행한다.

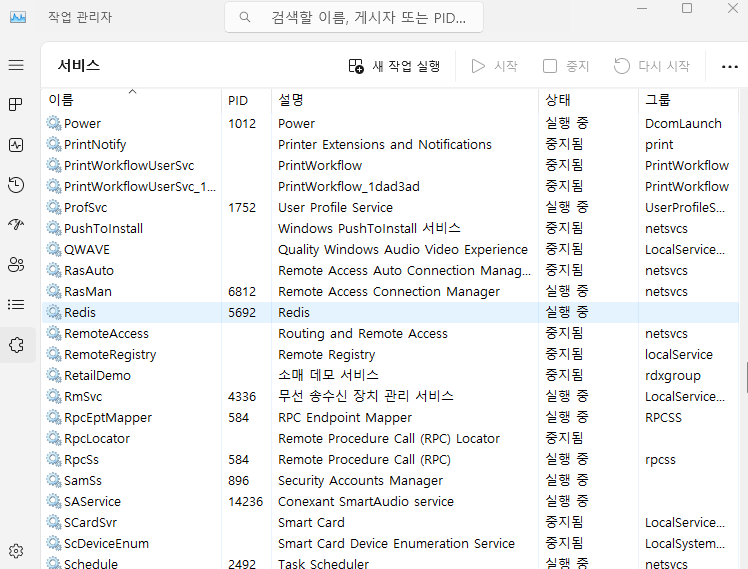
설치가 완료되면 서비스에 자동으로 등록되어 실행되며, 작업관리자 서비스 탭에서 확인이 가능하다.
레디스 서버를 실행 시켰다면, 레디스 명령어를 사용할 수 있는 redis-cli.exe을 실행시킨다.
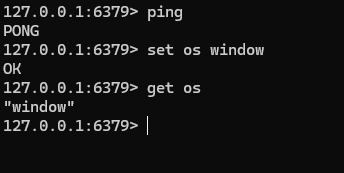
터미널이 뜨면, 레디스가 잘 작동이 되는지 테스트 해본다.
ping 명령어를 입력하여 확인(PONG)이 가능하다. set 명령어로 데이터를 key-value 형태로 입력이 가능하며 get으로 조회할 수 있다.
🔤 기본 명령어
저장
| 명령어 | 설명 |
|---|---|
| SET key value | key와 value를 저장한다. 이미 존재하는 key라면 덮어쓴다. |
| MSET key value [key value…] | 여러 개의 key-value 쌍을 한 번에 저장한다. 각각의 key가 이미 존재하면 덮어쓴다. |
| SETEX key seconds value | key, value를 저장하고 만료 시간(초 단위)을 설정한다. 만료 시간이 지나면 key는 자동 삭제된다. |
조회
| 명령어 | 설명 |
|---|---|
| KEYS pattern | 주어진 패턴과 일치하는 모든 key를 반환한다. ‘*‘는 모든 key를 의미한다. 🚨 주의: 성능 이슈로 실제 서비스에서는 사용을 피해야 한다. |
| GET key | 지정한 key에 해당하는 value를 가져온다. key가 없으면 nil을 반환한다. |
| MGET key [key…] | 여러 key의 value를 한 번에 가져온다. 존재하지 않는 key는 nil로 반환된다. |
| TTL key | key의 남은 만료 시간을 초 단위로 반환한다. -1은 만료시간 없음, -2는 key가 존재하지 않음을 의미한다. |
| PTTL key | key의 남은 만료 시간을 밀리초 단위로 반환한다. |
| TYPE key | 해당 key의 value 타입을 반환한다. (string, list, set, hash 등) |
삭제
| 명령어 | 설명 |
|---|---|
| DEL key [key…] | 지정된 key(들)을 삭제한다. 삭제된 key의 수를 반환한다. |
| UNLINK key [key…] | DEL과 유사하지만 비동기적으로 key를 삭제한다. 큰 데이터셋을 삭제할 때 Redis의 성능을 저하시키지 않도록 도와준다. |
수정
| 명령어 | 설명 |
|---|---|
| RENAME key newkey | key의 이름을 newkey로 변경한다. newkey가 이미 존재하면 덮어쓴다. |
| EXPIRE key seconds | key에 만료 시간(초 단위)을 설정한다. 만료 시간이 지나면 key는 자동 삭제된다. |
기타
| 명령어 | 설명 |
|---|---|
| RANDOMKEY | 현재 데이터베이스에서 무작위로 key를 하나 반환한다. 데이터베이스가 비어있으면 nil을 반환한다. |
| PING | Redis 서버 연결을 테스트한다. 서버가 정상이면 “PONG”을 반환한다. |
| DBSIZE | 현재 데이터베이스의 keyd의 총 개수를 반환한다. |
| FLUSHALL | Redis 서버의 모든 데이터베이스의 key를 전부 삭제한다. 데이터베이스 전체가 초기화 되므로 신중히 사용해야 한다. |
| FLUSHDB | 현재 선택된 데이터베이스의 모든 key를 삭제한다. 다른 데이터베이스에는 영향을 미치지 않으므로 사용 시 유의해야 한다. |
🔑 Key 네이밍 컨벤션
Redis에서는 다양한 네이밍 컨벤션이 존재하지만, 가장 중요한 원칙은 콜론(:)을 활용하여 계층적으로 의미를 구분하는 것이다. 이 방식은 key의 구조와 의미를 명확하게 전달한다.
예시:
users:100:profile: 사용자 집합(users) 내 ID가 100인 특정 사용자의 프로필 정보products:123:details: 상품 목록(products) 중 ID가 123인 상품의 상세 정보
이러한 네이밍 컨벤션을 채택함으로써 얻을 수 있는 이점:
- 향상된 가독성: key만으로도 데이터의 의미와 용도를 직관적으로 파악할 수 있다.
- 일관성 유지: 통일된 규칙을 따름으로써 코드의 일관성이 높아지고, 결과적으로 유지보수가 용이해진다.
- 효율적인 검색 및 필터링: 패턴 매칭을 이용해 특정 유형의 key를 쉽게 찾고 관리할 수 있다.
- 확장성 개선: 서로 다른 데이터 타입 간의 이름 충돌 가능성이 크게 줄어든다.
참고
Leave a comment